JSON for the SQL Server Developer

What is JSON?
JSON or JavaScript Object Notation is an open standard data format that represents data objects using attribute value pairs. It is commonly used as an asynchronous transport mechanism between browser and server in web applications. JSON has a small number of basic types including String, Number, Boolean, Object and Array. The JSON fragment below illustrates all of these types.
{ "givenName": "Geoffery",
"surName": "Smith",
"dateOfBirth": "15/11/1970",
"address" : {
"houseNameNo" : 29,
"street": "Acacia Avenue",
"locality": null,
"city": "Birmingham",
"postCode": "B1 6TY"
},
"contactNumbers" : [
{"telephoneNumber": "07971 656734", "isPrimary": "true" },
{"telephoneNumber": "0121 1234567" , "isPrimary": "false" }
]
}
Objects are represented as collections of name/value pairs enclosed in curly brackets. Name/value pairs are separated from each other with a comma and a colon is used to separate the key from the value in a key/value pair. Arrays are represented as a list of zero or more values enclosed in square brackets. To learn more about JSON see the official JSON website (http://www.json.org)
SQL Server's JSON Support
Before looking at JSON it makes sense to quickly review how SQL Server supports other semi-structured datatypes, namely XML. When Microsoft introduced XML support in SQL Server 2005 it did so using a native XML datatype, which uses an internal binary representation to store the XML data. Support for XML schemas was also included allowing XML columns to be typed according to a schema and XML data to be validated against a schema. Several supporting functions for manipulating and querying data with the XML type were provided along with dedicated XML indexes.
In contrast, SQL Server treats JSON as a string uses the VARCHAR or NVARCHAR datatype for storage. There is no support for schemas so the contents of the JSON cannot be validated against any kind of structure. Limited validation support, however, is provided by the ISJSON() function. This allows the content of a string to be validated to verify that they contain valid JSON. Similarly, there is no dedicated indexing support like that available for XML datatype. Despite these differences, those familiar with XML handling in SQL Server will find many similarities in the language constructs for manipulating and querying JSON data.
Consuming JSON Data
To demonstrate the use of the functions available for consuming and manipulating JSON data we will use data available from the Ergast Developer API (http://ergast.com/mrd/). The API provides historical motor racing data including details drivers, race results and circuit information. For our purposes we will use the results of the 2015 Formula 1 season. The raw JSON data can be retrieved from the following URL:
http://ergast.com/api/f1/2015/results.json?limit=10000
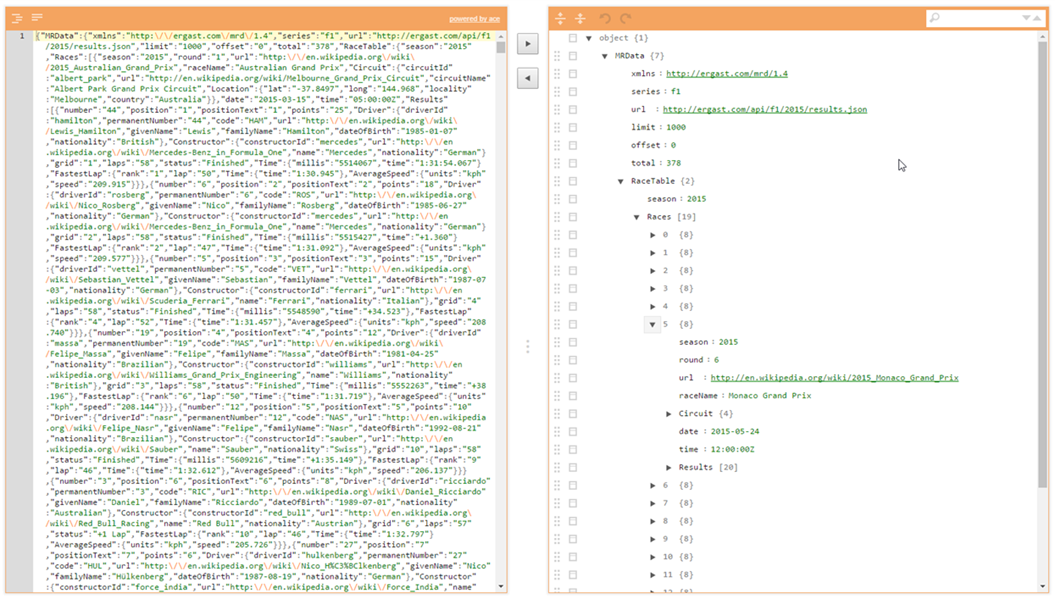
A formatted version of the data can be viewed using the following link.
The left-hand window shows the raw JSON and the right hand window contains a tree-view of the JSON in which the levels can be expanded and collapsed. Take a moment to browse through the data as this will help in understanding some of the queries that follow.
When it comes to consuming JSON data we have 4 options:
- JSON_VALUE() - Returns a scalar value from a JSON document. Similar to the value() method of the XML datatype.
- JSON_QUERY() - Returns a JSON fragment from a JSON string.
- OPENJSON() – Is a table-valued function that providers a tabular view of the JSON data.
- JSON_MODIFY() - Manipulates data within the JSON string. Similar to the modify() method of the XML datatype
JSON_VALUE()
Let’s assume that the race results JSON is held in a string @f1data. We can use the JSON_VALUE function to return the value from any of the key/value pairs in the JSON provided that the value being returned is a scalar value.
If we wanted to retrieve the value of the season key/value pair we could execute the following
SELECT JSON_VALUE(@f1data,'$.MRData.RaceTable.season')
The path that is passed as the second parameter of the JSON_VALUE function is used to navigate the structure of the JSON to locate the key of the value that you wish to return. Like XML the JSON is case sensitive so if we had called the JSON_VALUE but the following parameters then a NULL value would have been returned, because there is no key in the JSON document with upper case letters.
SELECT JSON_VALUE(@f1data,'$.MRData.RaceTable.SEASON')
This may catch you out and you may prefer to have an error raised when the particular key/value pair does not exist. To do this it is necessary to use the strict keyword at the beginning of the path parameter as shown below
SELECT JSON_VALUE(@f1data,'strict $.MRData.RaceTable.SEASON')
Running this statement will result in an error rather than returning NULL.
Msg 13608, Level 16, State 5, Line 11
Property cannot be found on the specified JSON path.
JSON_VALUE can also be used to retrieve values from arrays by specifying the array index in square brackets after the name of the Array. For example, in the query below we return the name of the 5th race (Monaco Grand Prix) from the Races array.
SELECT JSON_VALUE(@f1data,'$.MRData.RaceTable.Races[5].raceName')
One of the current limitations with the JSON_VALUE function is that its return result is limited to NVARCHAR(4000). Any data longer than this will be silently truncated unless the strict keyword is used. If you are retrieving data that is larger than this, then you will need to use the OPENJSON function, which we will cover later on.
JSON_QUERY()
The JSON_QUERY() function is useful in those situations when you want to extract a fragment of JSON from a large JSON document. For example, if we wanted to return the JSON object that represented the winning driver of the Monaco Grand Prix then we could use the following:
SELECT JSON_QUERY(@f1data,'$.MRData.RaceTable.Races[5].Results[0].Driver')
The path takes the 5 element of the Races array and then the first element of the results array returning the Driver object as shown below:
{
"driverId":"rosberg",
"permanentNumber":"6",
"code":"ROS",
"url":"http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg",
"givenName":"Nico",
"familyName":"Rosberg",
"dateOfBirth":"1985-06-27",
"nationality":"German"
}
When using the JSON_QUERY function you will notice that the fragment that is returned does not have the clickable link to open the JSON in a new window. This is because the JSON_QUERY() function returns an NVARCHAR(MAX) result. This may not be a problem in everyday use, but when debugging code it can be helpful to see the output in a new window, especially if the JSON fragment being returned is large. To get the results to return a clickable link then alias the function and use the FOR JSON PATH clause like so:
SELECT JSON_QUERY(@f1data, '$.MRData.RaceTable.Races[5].Results[0].Driver') AS Driver FOR JSON PATH
OPENJSON()
The OPENJSON() function returns a rowset (i.e. a table) from the JSON string that is passed to the function. The schema of the table returned by OPENJSON is influenced by the way in which it is called. When called without a result schema the OPENJSON function returns a table comprising the columns: Key, Value and Type. The Key column contains either the key name or a numeric array index depending on the type of the JSON object; the Value column contains the value(s) associated with the key; and the Type column contains a numeric identifier for the type of the value. A list of valid type identifiers can be found at https://msdn.microsoft.com/en-us/library/dn921885.aspx
The examples below illustrate some of the different ways the OPENJSON function can be used without result schema.
DECLARE @json NVARCHAR(MAX)=N'{
"driverId": "rosberg",
"permanentNumber": "6",
"code": "ROS",
"url": "http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg",
"givenName": "Nico",
"familyName": "Rosberg",
"dateOfBirth": "1985-06-27",
"nationality": "German",
"hairColour": "Blonde",
"Telephone": {
"mobile": "07999 123456",
"home": "01234 123456"
},
"favouriteFilms": [
"Cars",
"Cars 2",
"Canonball Run"
]
}'
-- return the full JSON object in tabular form
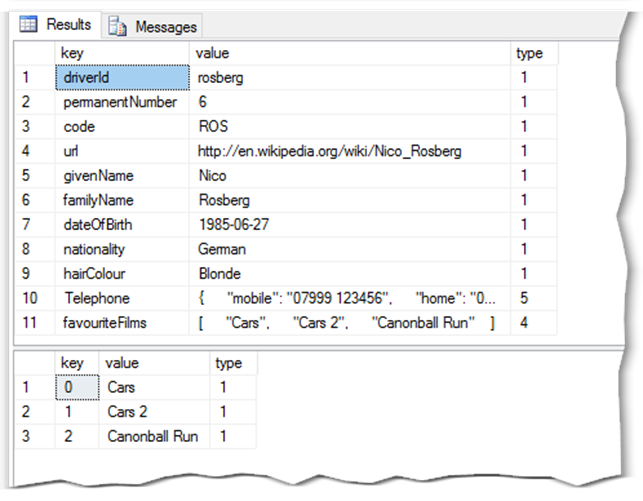
SELECT * FROM OPENJSON(@json)
--return a JSON array in tabular form
SELECT * FROM OPENJSON(JSON_QUERY(@json,'$.favouriteFilms'))
The first SELECT statement simply takes the root level JSON object and returns each key value pair in the object. The contents of the value column could either be a simple value, or in the case of complex types, such as objects or arrays then the value will be another JSON object. See for example the “Telephone” and “favouriteFilms” keys in the results below.
The second SELECT statement illustrates how the data for JSON array is returned by the OPENJSON function. The JSON_QUERY() function is first used to extract the array form the outer object and the OPENJSON serializes the array into tabular format, with the key value representing the value’s position in the array.
Using a results schema allows you to exercise more control over the output of the OPENJSON() function. If we take the JSON array below.
DECLARE @json NVARCHAR(MAX)=N'[{
"driverId": "rosberg",
"permanentNumber": "6",
"code": "ROS",
"url": "http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg",
"givenName": "Nico",
"familyName": "Rosberg",
"dateOfBirth": "1985-06-27",
"nationality": "German",
"hairColour": "Blonde",
"Telephone": {
"mobile": "07999 123456",
"home": "01234 123456"
},
"favouriteFilms": [
"Cars",
"Cars 2",
"Canonball Run"
]
},
{
"driverId":"alonso",
"permanentNumber":"14",
"code":"ALO",
"url":"http:\/\/en.wikipedia.org\/wiki\/Fernando_Alonso",
"givenName":"Fernando",
"familyName":"Alonso",
"dateOfBirth":"1981-07-29",
"nationality":"Spanish",
"hairColour": "Brown",
"Telephone": {
"mobile": "07774 123456",
"home": "02345 123456"
},
"favouriteFilms": [
"Planes",
"Planes 2",
"Canonball Run 2"
]
}
]'
We can use the following SELECT statement to return the data in tabular form
SELECT * FROM OPENJSON(@json) WITH ( driverId VARCHAR(10), code VARCHAR(3), url VARCHAR(255), givenName VARCHAR(50), familyName VARCHAR(50), Telephone_mobile VARCHAR(MAX) '$.Telephone.mobile', Telephone_home VARCHAR(MAX) '$.Telephone.home', favouriteFilms NVARCHAR(MAX) AS JSON )

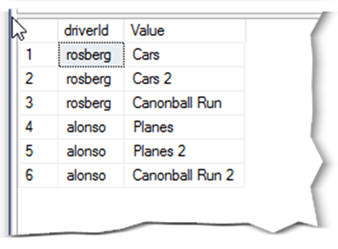
We can also combine calls to OPENJSON with and without a results schema to break out the favouriteFilms array into a table keyed on the driverId. This is illustrated in the following query, which uses a call to OPENJSON with a results schema to extract the driverId and the JSON formatted array. The OPENJSON function without a results schema is then called on the favouriteFilms array, returning a row for each array item.
SELECT driverId, st.[value] FROM OPENJSON(@json) WITH ( driverId VARCHAR(10), favouriteFilms NVARCHAR(MAX) AS JSON ) CROSS APPLY (SELECT * FROM OPENJSON(favouriteFilms) ) AS st
JSON_MODIFY()
So far, the functions we have looked at have been concerned with querying JSON data. The JSON_MODIFY function can be used to manipulate JSON strings. A key thing to be aware of when using the JSON_MODIFY function is that it operates on a copy of the JSON data. This is very different to the modify() XML function which updates the data in place. Consequently, you need to ensure that you capture and store the result of the JSON_MODIFY function.
To demonstrate the types of manipulation that are possible with the JSON_MODIFY function consider the following driver JSON string
DECLARE @driver NVARCHAR(MAX) = '{
"driverId": "rosberg",
"permanentNumber": "6",
"code": "ROS",
"url": "http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg",
"givenName": "Nico",
"familyName": "Rosberg",
"dateOfBirth": "1985-06-27",
"nationality": "German",
}'
Inserts
-- Insert a key/value pair
SELECT @driver = JSON_MODIFY(@driver,'$.hairColour','Brown')
-- Insert an Object
SELECT @driver = JSON_MODIFY(@driver,'$.Telephone',JSON_QUERY('{"mobile":"07234 654234","home":"01234 123456"}'))
-- Insert an Array
SELECT @driver = JSON_MODIFY(@driver,'$.favouriteFilms',JSON_QUERY('["Cars","Cars 2"]'))
Will result in the following JSON
{ "driverId": "rosberg", "permanentNumber": "6", "code": "ROS", "url": "http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg", "givenName": "Nico", "familyName": "Rosberg", "dateOfBirth": "1985-06-27", "nationality": "German", "hairColour": "Brown", "Telephone": { "mobile": "07234 654234", "home": "01234 123456" }, "favouriteFilms": [ "Cars", "Cars 2" ] }
Updates / Appends
--- Update a key value pair SELECT @driver = JSON_MODIFY(@driver,'$.hairColour','Blonde') -- Append to an array SELECT @driver = JSON_MODIFY(@driver,'append $."favouriteFilms"','Canonball Run') --- Update a nested object SELECT @driver = JSON_MODIFY(@driver,'$.Telephone.mobile','07999 123456')
Will result in the following JSON
{
"driverId": "rosberg",
"permanentNumber": "6",
"code": "ROS",
"url": "http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg",
"givenName": "Nico",
"familyName": "Rosberg",
"dateOfBirth": "1985-06-27",
"nationality": "German",
"hairColour": "Blonde",
"Telephone": {
"mobile": "07999 123456",
"home": "01234 123456"
},
"favouriteFilms": [
"Cars",
"Cars 2",
"Canonball Run"
]
}
Deletes
-- Remove a key value pair SELECT @driver = JSON_MODIFY(@driver,'$.Telephone.home',NULL) -- Remove an array SELECT @driver = JSON_MODIFY(@driver,'$.favouriteFilms,NULL)
Will result in the following JSON
{
"driverId": "rosberg",
"permanentNumber": "6",
"code": "ROS",
"url": "http:\/\/en.wikipedia.org\/wiki\/Nico_Rosberg",
"givenName": "Nico",
"familyName": "Rosberg",
"dateOfBirth": "1985-06-27",
"nationality": "German",
"hairColour": "Blonde",
"Telephone": {
"mobile": "07999 123456",
"home": "01234 123456"
}
}
Emitting JSON Data
The FOR JSON clause, like its cousin the FOR XML clause, is used to output query results in JSON format. FOR JSON can be used in one of two modes: AUTO or PATH. In PATH mode the user retains a degree of control as to how the JSON is formatted, whereas in AUTO mode the JSON is formatted automatically based on the structure of the SELECT statement. For example, the following query outputs a JSON string showing the creation date of the master and tempdb databases along with the files associated with each database.
SELECT d.database_id ,
d.name AS database_name,
d.source_database_id ,
d.create_date ,
files.file_id ,
files.name AS file.name,
files.type_desc
FROM sys.databases d
INNER JOIN sys.master_files AS files
ON files.database_id = d.database_id
WHERE
d.name IN ('master','tempdb')
FOR JSON AUTO;
The output of the above query is a JSON string that contains an array of objects (1 object per row of the sys.databases table). Rows from the joined sys.master_files table are nested within each “database” object as an array of “file” objects.
[
{
"database_id": 1,
"database_name": "master",
"create_date": "2003-04-08T09:13:36.390",
"files": [
{
"file_id": 1,
"file_name": "master",
"type_desc": "ROWS"
},
{
"file_id": 2,
"file_name": "mastlog",
"type_desc": "LOG"
}
]
},
{
"database_id": 2,
"database_name": "tempdb",
"create_date": "2016-06-16T20:34:41.237",
"files": [
{
"file_id": 1,
"file_name": "tempdev",
"type_desc": "ROWS"
},
{
"file_id": 2,
"file_name": "templog",
"type_desc": "LOG"
},
{
"file_id": 3,
"file_name": "temp2",
"type_desc": "ROWS"
},
{
"file_id": 4,
"file_name": "temp3",
"type_desc": "ROWS"
},
{
"file_id": 5,
"file_name": "temp4",
"type_desc": "ROWS"
}
]
}
]
In PATH mode more control of how the JSON is output is available. By aliasing columns with dot-separated names it is possible to nest the resulting JSON. For example, in the following query the state id and description columns have been aliased, which will result in the creation of a nested “state” object within the database object.
SELECT d.database_id AS [id],
d.name AS [name],
d.create_date AS [created_on],
d.state AS [state.id],
d.state_desc AS [state.description],
(SELECT
mf.file_id AS [id],
mf.name AS [name],
mf.type_desc AS [type]
FROM sys.master_files mf WHERE mf.database_id = d.database_id
FOR JSON PATH) files
FROM sys.databases d
WHERE
d.name IN ('master','tempdb')
FOR JSON PATH
Notice also that in PATH mode we have to use a subquery to return the files associated with a database to maintain the nesting within the JSON string. If we had not done this and kept the join clause then in PATH mode the results would be have been flattened.
[
{
"id": 1,
"name": "master",
"created_on": "2003-04-08T09:13:36.390",
"state": {
"id": 0,
"description": "ONLINE"
},
"files": [
{
"id": 1,
"name": "master",
"type": "ROWS"
},
{
"id": 2,
"name": "mastlog",
"type": "LOG"
}
]
},
{
"id": 2,
"name": "tempdb",
"created_on": "2016-06-16T20:34:41.237",
"state": {
"id": 0,
"description": "ONLINE"
},
"files": [
{
"id": 1,
"name": "tempdev",
"type": "ROWS"
},
{
"id": 2,
"name": "templog",
"type": "LOG"
},
{
"id": 3,
"name": "temp2",
"type": "ROWS"
},
{
"id": 4,
"name": "temp3",
"type": "ROWS"
},
{
"id": 5,
"name": "temp4",
"type": "ROWS"
}
]
}
]
It is also worth noting that by default the FOR JSON will omit any columns from the results that contain NULL values. Using the INCLUDE_NULL_VALUES option on the FOR JSON clause will force properties which are NULL to be included in the output.
There are a couple of other options that can be used with the FOR JSON clause. The ROOT option takes the results of the query and rather than returning a JSON array it returns an object with a property (key) named after the parameter provided to the ROOT option, which is itself an array of the query results. For example, adding the option ROOT(‘databases’) to the first query above
SELECT d.database_id ,
d.name AS database_name,
d.source_database_id ,
d.create_date ,
files.file_id ,
files.name AS file.name,
files.type_desc
FROM sys.databases d
INNER JOIN sys.master_files AS files
ON files.database_id = d.database_id
WHERE
d.name IN ('master','tempdb')
FOR JSON AUTO, ROOT('databases'), INCLUDE_NULL_VALUES;
Would result in the following output. Notice also that the INCLUDE_NULL_VALUES option has been specified and this has caused the “source_database_id” property to be included in the output with a value of NULL.
{
"Databases": [
{
"database_id": 1,
"database_name": "master",
"source_database_id": null,
"create_date": "2003-04-08T09:13:36.390",
"files": [
{
"file.id": 1,
"file.name": "master",
"type_desc": "ROWS"
},
{
"file.id": 2,
"file.name": "mastlog",
"type_desc": "LOG"
}
]
},
{
"database_id": 2,
"database_name": "tempdb",
"source_database_id": null,
"create_date": "2016-10-02T10:21:40.713",
"files": [
{
"file.id": 1,
"file.name": "tempdev",
"type_desc": "ROWS"
},
{
"file.id": 2,
"file.name": "templog",
"type_desc": "LOG"
},
{
"file.id": 3,
"file.name": "temp2",
"type_desc": "ROWS"
},
{
"file.id": 4,
"file.name": "temp3",
"type_desc": "ROWS"
},
{
"file.id": 5,
"file.name": "temp4",
"type_desc": "ROWS"
}
]
}
]
}
The final option WITHOUT ARRAY WRAPPER has the effect of removing the array wrapper from the JSON output. This would cause the output of the first query to look like this:
{
"database_id": 1,
"database_name": "master",
"source_database_id": null,
"create_date": "2003-04-08T09:13:36.390",
"files": [
{
"file.id": 1,
"file.name": "master",
"type_desc": "ROWS"
},
{
"file.id": 2,
"file.name": "mastlog",
"type_desc": "LOG"
}
]
},
{
"database_id": 2,
"database_name": "tempdb",
"source_database_id": null,
"create_date": "2016-10-02T10:21:40.713",
"files": [
{
"file.id": 1,
"file.name": "tempdev",
"type_desc": "ROWS"
},
{
"file.id": 2,
"file.name": "templog",
"type_desc": "LOG"
},
{
"file.id": 3,
"file.name": "temp2",
"type_desc": "ROWS"
},
{
"file.id": 4,
"file.name": "temp3",
"type_desc": "ROWS"
},
{
"file.id": 5,
"file.name": "temp4",
"type_desc": "ROWS"
}
]
}
SQL Server Management Studio and JSON
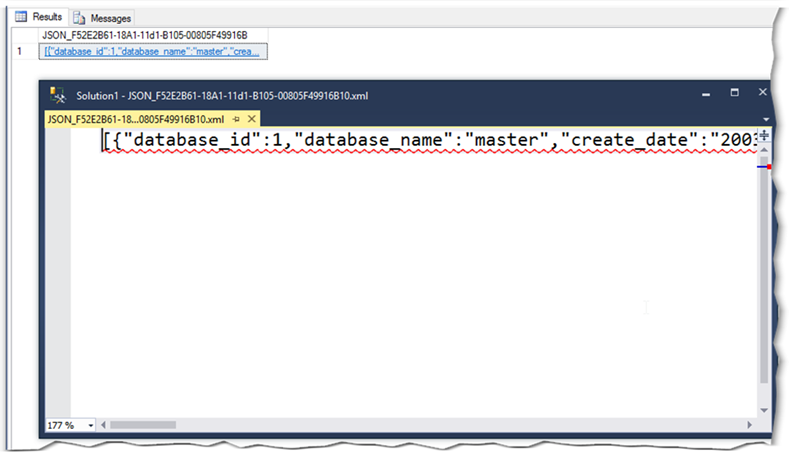
Working with JSON data within SQL Server Management Studio (SSMS) is somewhat disappointing when compared to the support provided for the XML datatype. Particularly when viewing the results of a query that returns a JSON string. Even though management studio displays a hyperlinked string of the JSON, clicking the link reveals an unformatted text window rather than the collapsible tree view that you get with XML. This means that any data returned by the FOR JSON clause will always be unformatted (see the screen grab below for an example). However, if the JSON stored in the database was formatted before it was stored then the formatting will be preserved when it is output. That said, this is still a long way from tree-viewer provided for XML data.
A slightly better experience is provided by Visual Studio which allows you to format the JSON in the output window using the CTRL + K + D keystroke.
There are also many online formatters available that will take a JSON string, format it and provide a collapsible tree view representation. However, cutting and pasting data between tools will inevitably slow down development and debugging efforts and also brings the risk that you could be sharing potentially sensitive data. This is something to consider carefully before using any third-party online formatting tools.
Recap
When working with JSON data there are few key things to take away.
- When writing JSON path statements remember that the paths are case sensitive.
- All JSON functions, with the exception of OPENJSON() function can be used with the compatibility level of the database at any available level. The OPENJSON() function requires that the database compatibility level be set at 13.
- THE JSON_VALUE function has a fixed return type of NVARCHAR(4000) and will truncate any data that is longer than this. Use the OPENJSON() function to work-around this limitation
- By default, the JSON functions operate in “lax” mode. This means that if the item targeted by a path statement cannot be found in the JSON string then a NULL value is returned. For this reason, consider using “strict” mode as this causes errors to be raised if items cannot be found in the JSON string. Similarly, strict mode can also be used to force errors where data is truncated by the JSON_VALUE() function.